Видеокарты. Серия процессоров Southern Islands
Архитектура графических процессоров AMD (ATI) не подвергалась существенным изменениям со времен серии Radeon HD 2000: вплоть до HD 6000 в GPU использовался VLIW-дизайн. Что это такое? Сначала вспомним, как работает центральный процессор в наших персоналках. Современные CPU - суперскалярные, то есть их вычислительные блоки могут выполнять несколько инструкций из одного потока одновременно. Но инструкции при этом должны быть независимыми друг от друга, поэтому процессор непрерывно проверяет, когда можно выполнять параллельные операции, а когда нужно подождать разрешения очередной зависимости. Кроме того, CPU занимается предсказанием ветвлений и может делать часть работы заранее (out-of-order). Оптимизация этих функций - сложная техническая задача, а схемы, на которых они построены, занимают добрую часть кристалла CPU.
Но есть другой путь: задать порядок исполнения инструкций на этапе компиляции кода. Компилятор сам находит инструкции, которые можно выполнять одновременно, и формирует из них длинные составные конструкции. Отсюда и термин VLIW - very long instruction word. VLIW в общем случае показывает высокую эффективность, когда код содержит мало зависимостей, а ход программы предсказуем. Компилятор «знает» код от начала до конца и может задать исполнение определенных фрагментов с большим запасом по времени. Но планирование получается жестким, и в случае когда ход программы зависит от внешних данных, хитроумная компиляция уже мало помогает, исполнительные блоки простаивают и производительность идет вниз.
Но рендеринг 3D-графики - предсказуемая задача и отлично распараллеливается. Поэтому ставка на VLIW, которую сделала тогда еще независимая канадская компания, себя полностью оправдала. Переложив функции планировщика на компилятор, ATI могла делать относительно компактные чипы с бешеными сотнями исполнительных элементов внутри, и видеокарты в результате получились относительно недорогими. Звездный час VLIW в исполнении AMD пришелся на время Radeon HD пятитысячной серии, когда дебют архитектуры Fermi от NVIDIA (GeForce 400) немного забуксовал. И неудивительно, ведь «зеленым» приходится делать огромные чипы, вплоть до трех миллиардов транзисторов. И даже сейчас, когда в адаптерах GeForce 500 архитектура Fermi уже работает на полную мощность, а топовые ускорители NVIDIA побеждают в бенчмарках продукцию AMD, шеститысячные Radeon все еще обеспечивают отличную производительность в играх.
В таком случае, зачем AMD решилась на столь резкий поворот? Казалось бы, достаточно немного отполировать дизайн GPU, нарастить вычислительных блоков тут и там, внедрить более тонкий технологический процесс — и VLIW будет жить долго и счастливо. Зачем тратить время и деньги на разработку совершенно новой архитектуры? Но дело не только и не столько в играх. GPU медленно превращаются из устройств, предназначенных исключительно для 3D-рендеринга, в процессоры общего назначения (GPGPU - general purpose GPU), которые можно использовать для любых массированных параллельных вычислений. Однако на сегодняшний день вышло так, что если мы говорим GPGPU, то подразумеваем CUDA. Ни родной для «красных» API под названием ATI Stream, ни Open CL не имеют такой популярности, как CUDA от NVIDIA. Между тем AMD очень хочет откусить кусок от этого рынка, но чтобы это стало возможным, со старой доброй архитектурой VLIW придется расстаться. Для неграфических вычислений она не подходит, ибо они менее предсказуемы, чем 3D-рендеринг, и GPU просто не в состоянии работать в полную силу.
⇡ Архитектура Graphics Core Next
Возьмем последнего представителя VLIW-архитектуры от AMD, процессор Cayman, который лежит в основе адаптеров Radeon HD 6950/6970/6990. Основным компонентом шейдерного домена у него является SIMD Engine - блок из шестнадцати потоковых процессоров. Все они одновременно исполняют одну VLIW-инструкцию, но применительно к разным данным (потому и SIMD - single instruction, multiple data). В свою очередь, в одной VLIW-инструкции может быть упаковано вплоть до четырех скалярных операций, что соответствует четырем ALU внутри одного потокового процессора.

Строительный блок ядра Graphics Cores Next (GCN) называется Compute Unit, и он устроен совершенно по-другому. В нем тоже 64 ALU, но они разделены на четыре отдельных векторных SIMD-модуля по 16 штук плюс блок планировщика. Проще говоря, раньше параллелизм был реализован за счет нескольких операций в одной инструкции, а теперь за счет нескольких отдельных SIMD-блоков. И если производительность старой архитектуры зависит от того, сколько скалярных операций компилятор может закодировать в одной VLIW-инструкции, то Compute Unit в ядре GCN может динамически распределять нагрузку между SIMD-блоками.

Нагрузка для параллельного исполнения в SIMD-блок поступает в виде массива (wavefront) из 64 инструкций, который выполняется за четыре цикла. И хотя одновременно в работе могут быть только четыре массива, еще 28 находятся у Compute Unit в прямом доступе, за счет чего планировщик и получает пространство для маневра. В ситуации, когда зависимость в коде мешает комбинированному SIMD-блоку VLIW-процессора работать на полную мощность, отдельные SIMD-блоки чипа GCN просто переключатся на другие массивы из той же задачи либо вовсе на другие задачи.

Изюминка GCN - отдельный скалярный модуль в каждом Compute Unit. Он предназначен для разовых операций, не укладывающихся в wavefront (что избавит SIMD-модули от неэффективного использования), а еще - для контроля исполнения программы: условных ветвлений, переходов и прочих событий, которые Cayman переваривал с трудом. Скалярный модуль выполняет одну операцию за цикл.
Кеш-память
Новая конструкция исполнительных модулей требует более быстрой и объемной кеш-памяти по сравнению c VLIW-дизайном. У каждого CU есть отдельный кеш L1 объемом 16 Кбайт плюс хранилище для инструкций и данных на 16 и 32 Кбайт, общее для четырех CU, - буфер для разделения данных между массивами. Еще есть полностью когерентный кеш L2, поделенный на порции по 64 Кбайт между двухканальными контроллерами памяти. В нем хранятся копии вышеупомянутых буферов

Шины кешей L1 и L2 имеют разрядность 64 байт. AMD сообщает, что пропускная способность L1 достигает почти 2 Тбайт/с, а L2 - 700 Гбайт/с, и, судя по всему, здесь имеется в виду суммарное значение для процессора с 32 CU.
Для сравнения: у Cayman каждый SIMD-модуль имеет кеш L1 объемом 8 Кбайт с шиной 16 Байт.
Обработка геометрии, растеризация
О собственно графических компонентах чипа в презентациях AMD, сопровождающих релиз, сказано немного. Судя по блок-схеме, их внутреннее устройство не изменилась, только «Тесселятор» прокачался до девятой версии и обеспечивает гигантский прирост быстродействия в соответствующих задачах.

Между тем, если верить информации из посторонних источников и слайдам самой AMD с июньского Fusion Development Summit, то изнутри Geometry Engine и Tesselator выглядят совсем по-другому. Как и Cayman, ядро GCN содержит два Graphics Engine, но если раньше они состояли из отдельных блоков для растеризации, тесселяции и так далее, то теперь в каждом GE может быть произвольное количество конвейеров для обработки пикселей и геометрических примитивов.

Вероятно, такой дизайн поможет производителю легко наращивать графическую мощь либо выпускать бюджетные GPU, урезанные по этой части. Быстрая работа с геометрией придется в современных играх как нельзя кстати.
PCI-E 3.0
Заголовок говорит за себя: AMD внедрила шину PCI-E нового поколения со вдвое большей пропускной способностью. Непонятно, нужна ли она сегодня для 3D-рендеринга, но для неграфических расчетов наверняка пригодится. AMD внесла в архитектуру GCN массу нововведений с далеким прицелом на такое применение и специальную функцию графики, которая тоже отлично сочетается с новым интерфейсом.
Новые функции GCN
В GCN есть два дополнительных блока распределения команд под названием Asynchronous Compute Engine, которые работают совершенно независимо друг от друга и графического командного процессора. AMD планирует открыть доступ к ACE через Open CL, и тогда в распоряжении программистов окажутся три отдельных устройства, каждое со своей очередью команд. Кроме того, по информации из третьих рук, ACE обеспечивает внеочередное исполнение на уровне отдельных задач. Сами CU хоть и поумнели по сравнению с SIMD-модулями VLIW-архитектуры, но могут обрабатывать свои wavefront’ы строго в прямом порядке.

Ядро GCN и центральный процессор компьютера могут иметь общее адресное пространство. В таком случае все инструкции, которые попадают на исполнение в GPU, указывают на адреса в пространстве x86-64, а он уже самостоятельно перекодирует их в адреса локальной видеопамяти при помощи специального модуля. В результате GPU получает прямой доступ к системной памяти. Кроме того, ядро GCN наделили рядом функций для поддержки языков высокого уровня: виртуальными функциями, указателями, рекурсией и так далее. Это позволит программистам писать универсальный код, пригодный для исполнения на CPU или на GPU.
Новые GPU полностью совместимы с API OpenCL 1.2, DirectCompute 11.1 (и DirectX 11.1 как таковой) и C++ AMP. Появились специальные инструкции, полезные для производства мультимедийного контента. Кроме того, чипы на базе архитектуры GCN стали первыми GPU со встроенным кодировщиком видео стандарта H.264, который можно будет использовать, как только AMD выпустит необходимую библиотеку софта.
В свою очередь, декодер приобрел поддержку нескольких дополнительных форматов: MVC, MPEG-4/DivX и Dual Stream HD + HD. Вообще, видеокарты Radeon были сильны по части воспроизведения видео еще во времена ATI. У семитысячной серии есть масса «улучшайзеров» картинки, например алгоритм Steady Video, устраняющий дрожание камеры.
Partially Resident Textures - еще один трюк с виртуальной памятью, который предназначен уже для 3D-рендеринга: приложение или шейдер работают с адресным пространством, превышающим объем набортной памяти адаптера, а она сама выступает лишь в качестве быстрого кеша. Таким образом можно использовать текстуры объемом до 32 Тбайт, порции которых GPU будет динамически подкачивать поближе к себе. Поддержка со стороны ОС в этом не требуется.
Тормоза, которые неизбежно возникнут при загрузке текстур из системной памяти, AMD отчасти компенсирует использованием MIP mapping’a. Гигантская текстура наверняка будет храниться в нескольких вариантах с различным разрешением (mipmaps). Каждый из них разделен на фрагменты объемом 64 Кбайт. Когда адаптеру требуется определенный фрагмент, и он уже есть в локальной видеопамяти, то нет проблем. Если же фрагмента не оказалось, то программа может немедленно потянуть его из системной памяти, а может отложить чтение и взять для текущего кадра соответствующую копию фрагмента с низким разрешением (если он уже есть в видеопамяти).

Небольшое дополнение к вопросу о тесселяции. В GCN реализован алгоритм Ptex (Per-face texture mapping). В общем случае в 3D-моделировании текстура накладывается на модель целиком и вершины необходимо аккуратно совмещать с нужными участками двухмерного полотна. Нетрудно представить, как аппаратная тесселяция, плодящая дополнительные вершины, усложняет задачу дизайнера. При использовании Ptex на каждый полигон накладывается отдельная текстура, в результате - никаких видимых стыков. Кроме того, Ptex позволяет упаковывать в один файл текстуры с различным разрешением.

Наконец, AMD немного поработала над анизотропной фильтрацией с целью устранить едва заметное мерцание на текстурах высокого разрешения. Изменение алгоритма не должно сказаться на быстродействии.

Контроль энергопотребления
AMD отмечает, что производители GPU и видеокарт всегда перестраховываются на счет энергопотребления и устанавливают тактовые частоты с учетом пиковой нагрузки, которая возможна лишь в самых жадных приложениях или даже в стресс-тестах (FurMark. OCCT). А в обычных играх графический процессор мог бы работать на более высокой частоте. Для того чтобы всегда выжимать из GPU максимум, предназначена технология PowerTune - калькулятор, который в реальном времени с интервалами в единицы миллисекунд рассчитывает энергопотребление карты на основе анализа выполняемой задачи (без всяких аналоговых сенсоров). И если есть возможность, тактовая частота GPU увеличивается. Заметьте, это не сброс частоты относительно номинала при достижении порога мощности, а наоборот - точно выверенный динамический разгон.

А еще ядро GCN умеет полностью отключаться, когда на экране долго ничего нет, и останавливать кулер (технология ZeroCore). В конфигурации CrossFire процессоры на дополнительных картах (и на одной - тоже) и вовсе не работают без 3D-нагрузки.

Eyefinity 2.0
Вместе с Radeon HD 7000 дебютирует вторая версия технологии Eyefinity, которая принесла массу нововведений. Многие представленные «фичи» не нуждаются в комментариях, поэтому перечислим их кратко:
- Официально поддерживаются конфигурации с пятью дисплеями в ряд в альбомной или портретной ориентации.
- Центральный монитор в ряду теперь может быть больше остальных по вертикали.
- Одновременная работа Eyefinity, AMD HD3D и CrossFire.
- Максимальное разрешение комбинированного экрана - 15х15 тысяч пикселей.
- Произвольные разрешения.
- Перемещение панели задач Windows на любой экран.
- Вывод отдельных аудиопотоков на несколько дисплеев.
Новые Radeon поддерживают DisplayPort 1.2, а значит - технологию Multi-Stream. С ее помощью можно подключать к одному выходу три дисплея по цепочке или через специальный хаб. Причем на выходе хаба может быть не только DisplayPort, но и интерфейсы HDMI, DVI и VGA. AMD обещает, что хабы появятся в продаже летом 2012 года.

HDMI-выход соответствует стандарту 1.4а, поэтому может передавать двойной сигнал на 3D-телевизор с частотой 24 кадра на каждый канал. А специально для игр есть поддержка 3 GHz HDMI с частотой 60 Гц на канал.
Кроме того, стандарты DisplayPort 1.2 HBR 2 и 3 GHz HDMI пригодятся для подключения грядущих дисплеев с разрешением 4096x2160.
⇡ Radeon HD 7970
Технические характеристики
HD 7970 - одночиповый флагман линейки, представляющий архитектуру GCN во всей мощи. Его GPU называется Tahiti и содержит 32 CU (Compute Units), устройство которых подробно описано выше. Если пересчитать это на количество отдельных ALU, как AMD делала до сих пор, то получится 2048 штук - в полтора раза больше, чем в ядре Cayman! И блоков TMU (texture mapping units) в Tahiti тоже 128 против 96. Шина памяти - 384-битная вместо 256-битной. Если учесть, сколько дополнительной логики добавили в архитектуру, то совершенно не удивительно, что Tahiti состоит из 4,31 миллиарда транзисторов. Просто для сравнения: в Cayman - 2,64 миллиарда, а в GF110 от NVIDIA - три. Работает все хозяйство на частоте 925 МГц. Внешний вид, конструкция

В оформлении семитысячной серии AMD отступила от брутальных форм Radeon HD 6000 и выбрала броский дизайн с плавными линиями и глянцевой поверхностью кожуха. Вернулся узнаваемый красный текстолит, в этот раз - с малиновым оттенком. По габаритам Radeon HD 7970 не отличается от предшествующих одночиповых флагманов AMD/ATI.

Продукция кирпичного завода AMD
Карта тяжелая. Берешь в руку - и чувствуется мощь. Все дело в системе охлаждения с крупной испарительной камерой, приделанной к толстой раме. Со времен Radeon HD 6970 конструкция не претерпела больших изменений, разве что вентилятор-турбинка стал шире.


Для лучшего охлаждения с заглушки убрали один порт DVI, чтобы целиком занять слот выхлопной решеткой.

С задней стороны, как и раньше, есть прижимная крестовина. От сплошной крышки решили отказаться.

На печатной плате, как и у HD 6970, есть переключатель между основным и резервным BIOS. А еще по задней поверхности разбросано несколько мелких сдвоенных переключателей неизвестного назначения, которые мы, от греха подальше, решили не трогать. Возможно, что перед нами лишь инженерный образец HD 7970 и на серийных платах этих странных элементов уже не будет.


В хвосте платы расположены семь катушек индуктивности и восьмифазный контроллер напряжения CHiL CHL8228G, чему, без сомнения, будут рады оверклокеры, ведь о н уже использовался на картах Radeon HD 6970, . Скорее всего, и схема питания карты организована по-старому: шесть фаз приходятся на GPU и одна отдана для питания внутренних цепей микросхем GDDR5. В противоположном углу платы находится двухфазный чип uP1509P от uP Semiconductor со своей катушкой, который, по аналогии с HD 6970, должен контролировать напряжение на буферах ввода-вывода видеопамяти.
AMD решила начать новую битву за господство на рынке GPU. Но сегодня обоим производителям, AMD и Nvidia, приходится сталкиваться с новыми вызовами и работать в новых условиях. В частности, AMD приходится переходить на новую технологию производства 28 нм, да и полностью новую архитектуру GPU, как оказалось. NVIDIA тоже планирует перейти на 28 нм, но только через несколько месяцев, и с новой архитектурой. Но AMD оказалось первой, и в нашей статье мы поговорим о новом поколении GPU в виде AMD Radeon HD 7970.
AMD считает, что игры на ПК ждёт бурное развитие, причём в ближней перспективе - особенно с учётом того, что приставки обновляются довольно долго. А поскольку современные графические движки выигрывают от возможностей передовых видеокарт, то подобное развитие будет только усиливаться. В прошлом году оборот рынка игр для ПК составил 15 млрд. долларов, и к 2013 году ожидается рост до 20 млрд. долларов. И не забывайте о том, что геймеры сегодня предпочитают играть на всё более высоком разрешении. Разрешение 1080p уже стали де-факто стандартом, что подкрепляется и стремительно дешевеющими дисплеями с большой диагональю. Кроме того, AMD фокусируется на более высокой эффективности GPU и на вычислительные возможности GPU. Последняя сфера для AMD сегодня очень важна, поскольку компания желает обойти ограничения, выявленные у GPU архитектуры Cayman.

На данный момент AMD представила только Radeon HD 7970, как можно видеть на слайде, но в линейке Radeon HD 7900 должны вскоре появиться новые видеокарты.
| NVIDIA GeForce GTX 570 |
NVIDIA GeForce GTX 580 |
AMD Radeon HD 6950 | AMD Radeon HD 6970 | AMD Radeon HD 7970 | |
| GPU | GF110 | GF110 | Cayman PRO | Cayman XT | Tahiti XT |
| Техпроцесс | 40 нм | 40 нм | 40 нм | 40 нм | 28 нм |
| Количество транзисторов | 3 млрд. | 3 млрд. | 2,6 млрд. | 2,6 млрд. | 4,3 млрд. |
| Площадь кристалла | 530 мм² | 530 мм² | 389 мм² | 389 мм² | 365 мм² |
| Тактовая частота GPU | 732 МГц | 772 МГц | 800 МГц | 880 МГц | 925 МГц |
| Тактовая частота памяти | 950 МГц | 1000 МГц | 1250 МГц | 1375 МГц | 1375 МГц |
| Тип памяти | GDDR5 | GDDR5 | GDDR5 | GDDR5 | GDDR5 |
| Объём памяти | 1280 Мбайт | 1536 Мбайт | 2048 Мбайт | 2048 Мбайт | 3072 Мбайт |
| Ширина шины памяти | 320 бит | 384 бит | 256 бит | 256 бит | 384 бит |
| Пропускная способность памяти | 152 Гбайт/с | 192 Гбайт/с | 160 Гбайт/с | 176 Гбайт/с | 264 Гбайт/с |
| Модель шейдеров | 5.0 | 5.0 | 5.0 | 5.0 | 5.0 |
| DirectX | 11 | 11 | 11 | 11 | 11.1 |
| Количество потоковых процессоров | 480 (1D) | 512 (1D) | 1408 (352 4D) | 1536 (384 4D) | 2048 (1D) |
| Тактовая частота потоковых процессоров | 1464 МГц | 1544 МГц | 800 МГц | 880 МГц | 925 МГц |
| Количество текстурных блоков | 60 | 64 | 88 | 96 | 128 |
| Количество ROP | 40 | 48 | 32 | 32 | 32 |
| Максимальное энергопотребление | 219 Вт | 244 Вт | 200 Вт | 250 Вт | 250 Вт |
| Минимальное энергопотребление | - | 30-32 Вт | 20 Вт | 20 Вт | 2,6 Вт |
| CrossFire/SLI | SLI | SLI | CrossFireX | CrossFireX | CrossFireX |
Видеокарта Radeon HD 7970 базируется на GPU "Tahiti XT", который производится по 28-нм техпроцессу. В общей сложности графический процессор насчитывает 4,3 млрд. транзисторов. Для сравнения, процессоры Intel Sandy Bridge-E (за исключением четырёхъядерных моделей) имеют 2,27 млрд. транзисторов. А предшественник из семейства Cayman Radeon HD 6900 работал с 2,6 млрд. транзисторов. Площадь кристалла составляет 365 мм². Как видим, площадь чуть меньше 389 мм² у GPU "Cayman", которые при этом производятся по 40-нм техпроцессу. GPU GF110 от NVIDIA содержит 3 млрд. транзисторов на площади 530 мм². Большая часть бюджета транзисторов GPU была потрачена на 2048 потоковых процессоров. GPU и потоковые процессоры работают на тактовой частоте 925 МГц. AMD решила сохранить ту же самую память, что и у Radeon HD 6970, то есть GDDR5 на 1375 МГц. Но интерфейс памяти был расширен с 256 бит до 384 бит, что обеспечило увеличение пропускной способности памяти до 264 Гбайт/с. Кроме того, и ёмкость возросла с 2048 Мбайт до 3072 Мбайт. У Radeon HD 7970 работают 128 текстурных блоков и 32 конвейера растровых операций (ROP) - мы получаем прирост текстурных блоков по сравнению с Radeon HD 6970, но количество ROP осталось прежним. AMD указала максимальное энергопотребление для Radeon HD 7970 на уровне 250 Вт, которое также является предельным значением для PowerTune. Типичное энергопотребление видеокарты составляет 210 Вт. У Radeon HD 6970, напомним, максимальное энергопотребление составляло 250 Вт, а типичное под нагрузкой - 190 Вт. Благодаря технологии ZeroCore Power (подробнее о ней чуть ниже) энергопотребление в режиме бездействия не превышает три ватта.

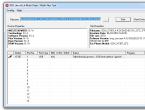
GPU-Z 0.5.7, как можно видеть на скриншоте, корректно отображает не все данные AMD Radeon HD 7970. На нашей тестовой системе Socket 1366 интерфейс был указан как PCI Express 3.0 x16, а тактовая частота - 500 МГц. Также приведены некорректные значения для пиксельной и текстурной пропускной способности. Правильные значения: 925 МГц для GPU, 29,6 Гпиксель/с и 118,4 Гтексель/с.
Видеокартами High-End класса уже никого не удивить, ведь производители поняли, что для большинства любителей поиграть в ресурсоёмкие компьютерные игры нового поколения мощность видеоадаптера на первом месте. Вот только цена устройства может остановить потенциального покупателя. Для привлечения внимания создаются промежуточные модификации устройств, которые нацелены на топовый сегмент, но цена их значительно ниже аналогов.
В данной статье речь пойдёт об одном из таких игровых видеоустройств - видеокарте HD 7970 от известного бренда, которые построили свои решения на чипе AMD. Первостепенной задачей производителя было снизить стоимость видеоадаптера, сохранив достойную игровую мощность.
Достойный конкурент
Когда речь заходит о продукции Nvidia, доступной по цене, то обнаруживается, что производитель просто предлагает урезанные версии своего флагмана Geforce Titan, в этом можно убедиться, сравнив чипы устройств и изучив их архитектуру. В компании AMD могли таким же способом предложить удешевлённые модификации чипа Radeon R9, однако делать этого не стали. Видеокарта HD 7970 получила совершенно новую платформу с применением всех современных технологий, благодаря чему превзошла по производительности все устройства, предложенные конкурентом в той же ценовой нише (15-20 тысяч рублей).
О том, что в результате получилось достойное игровое устройство по доступной цене, можно судить по изобилию устройств, построенных на данном чипсете. Все известные взялись за выпуск продукции на базе AMD Radeon HD 7970. На рынке покупатель может обнаружить даже несколько модификаций от одного изготовителя - это достойный показатель для многих юзеров.
В заводской упаковке
Доступную цену на рынке видеокарт устройству обеспечивает 28 нм технология с архитектурой GCN, имеющая в наличии всего одно графическое ядро (у всех топовых устройств их два). Благодаря современным технологиям, производителю удалось установить на чипе HD 7970 около 4,3 миллиарда транзисторов.

Графическое ядро работает на частоте 925 мегагерц, но как уверяют владельцы в своих отзывах, это минимальный показатель, который легко увеличивается, было бы достойное охлаждение. Установлено 128 текстурных блоков и 32 ROP. Память работает на частоте 1375 МГц (эффективная 5500), имеет объём 3 гигабайта и общается с компьютером по 384-битной шине. Кстати, на плате есть распайка для установки дополнительных модулей памяти, так что стоит ожидать новинок от производителей, имеющих 6 гигабайт на борту (возможно и с шиной 512 бит).
Высокая производительность видеоадаптера привела к увеличению электропотребления - 250 Вт в максимальной нагрузке очень напоминают продукты конкурента Nvidia. Довольно странно видеть продукцию AMD с такими ресурсоёмкими запросами (раньше ограничения были до 130 Вт).
Разогнанный вариант
Следуя тенденциям рынка видеоадаптеров, завод-изготовитель решил создать улучшенную модификацию своего устройства для требовательных пользователей (у Nvidia давно используется такая схема с созданием модификаций «Ti»). Видеокарта HD 7970 GHz Edition поступила в продажу в разогнанном виде: графическое ядро работает на частоте 1050 МГц, а видеопамять имеет 1500 МГц (6000 МГц). Стоит отметить, что производитель больше никаких изменений не внёс: ожидаемое увеличение пропускной способности свыше 384 бит и увеличение объёма памяти до 6 гигабайт не произошло. Увеличилась только цена. Как отмечают специалисты в своих отзывах, покупка явно окажется нерациональной, ведь у продуктов конкурента приставка «Ti» однозначно назначается устройствам с увеличенной пропускной способностью шины памяти.
Внешний вид и охлаждение
Всё-таки настал тот момент, когда для монтажа игрового устройства AMD требуется вместительный корпус стандарта Tower ATX. Ведь длина адаптера составляет 38 сантиметров, а занимает он два слота в системном блоке, явно претендуя на третий для достойного забора воздуха для охлаждения. Элементы размещены компактно: вокруг графического ядра установлены чипы памяти, а силовые элементы не разбросаны по всему периметру устройства, а аккуратно впаяны в один блок.

Видеокарта на базе чипа AMD Radeon HD 7970 имеет приятную на вид систему охлаждения. Алюминиевая секция радиатора является цельной и закрывает две трети печатной платы, основание её сделано из меди, что обеспечивает лучший отвод тепла от нагревающихся элементов. В хвосте видеоадаптера установлен фирменный турбовентилятор. Вся система охлаждения плотно закрывается защитным кожухом, который не позволяет нагретому воздуху возвращаться в корпус устройства, а выводится наружу через решётку
Недорогое решение
Самая дешёвая на российском рынке видеокарта HD 7970, отзывы о которой носят лишь положительный характер, представлена известным тайваньским брендом ASUS. Впервые за последнее время производитель не стал устанавливать собственную систему охлаждения, доверившись заводу-изготовителю. Вообще, компания ASUS сильно удивила своих поклонников, обеспечив устройство достойной комплектацией: всевозможные переходники для мониторов, разветвитель для подключения питания, мостик CrossFireX для подключения нескольких видеокарт.
Внешне видеоадаптер ASUS отличается от начального продукта AMD лишь надписью на кожухе радиатора, поэтому всё внимание пользователя приковано к техническим характеристикам устройства. Поставляемая в комплекте утилита ASUS GPU Tweak расставила всё по своим местам: великолепный разгон, демонстрирующий высокую производительность видеоадаптера, является главным достоинством производителя. Графическое ядро показывает стабильную работу на частоте 1200 МГц, а модуль памяти практически не нагревается на частоте 1635 МГц (6500 МГц).
Ледяная свежесть
Видеоадаптер 7970 компании HIS, как всегда, привлекает покупателей к своим продуктам эксклюзивным внешним видом и достойной системой охлаждения. Заявленный производителем уровень шума в 15 дБ явно не является маркетинговым ходом, ведь технологи компании полностью видоизменили систему питания видеокарты, установив ШИМ-контроллер собственного производства и увеличив количество фаз.

Алюминиевый радиатор закрывает всю поверхность печатной платы и пронизан медными трубками, которые в результате сводятся на сердечнике, примыкающем к графическому ядру. Сверху установлен металлический защитный кожух с двумя огромными вентиляторами, на низких оборотах очень эффективно создающими мощный поток воздуха, способный быстро отвести тепло от нагревающихся элементов.
В заводском исполнении частота ядра HD 7970 составляет 1050 МГц, а память работает на 1400 МГц, однако, как отмечают пользователи в своих отзывах, эти показатели ничто, по сравнению с потенциалом в разгоне: 1125 МГц по ядру и 1575 МГц по памяти обеспечивают великолепную производительность в играх.
Типичная модель известного производителя
А вот компания Sapphire разочаровала своих поклонников, ведь производитель просто взял продукт AMD HD 7970 и на кожухе устройства прикрепил свою наклейку. Естественно, никаких дополнительных доработок на печатной плате не было произведено. Привлекает внимание устройство на рынке лишь своей ценой (15000 рублей), которая по карману многим любителям динамических игр.
Стандартным разгоном по ядру до 1200 МГц уже никого не удивить, а вот память показывает стабильность работы на частоте 1785 МГц (эффективная 7140 МГц). Довольно неплохие показатели в тестовых приложениях и играх омрачаются работой системы охлаждения. По всей видимости, сильный нагрев ядра и чипов памяти заставляет турбовентилятор работать на максимальной мощности.
Срочная реабилитация
Видимо, осознав свои ошибки, компания Sapphire решила срочно реабилитироваться на рынке видеоадаптеров. Маркетологи презентовали сразу два продукта: видеокарты Radeon HD 7970 Vapor-X и Toxic Edition, которые поступили в продажу в двух вариациях каждая: с тремя и шестью гигабайтами оперативной памяти на борту. Совсем другое дело - сразу видно, что перед покупателями серьёзный бренд.

Видоизменению поддалась вся система питания: были установлены 8+2 фазы, которые значительно снизили энергопотребление видеоадаптера. Стоит отметить, что производитель установил фирменные контроллеры питания и сменил все ёмкости печатной платы на твердотельные накопители. Меди в производстве не жалели: основание радиатора, секции и трубки для отвода тепла выполнены из этого благородного металла.
Достойное охлаждение - залог успеха любого разгона. Графическое ядро показывает стабильную работу на частоте 1250 МГц, а память прекрасно работает на 1600 МГц. Потенциал к дальнейшему разгону есть, но сразу же появляется шум в работе двух небольших вентиляторов.
Бесшумный монстр
Компания PowerColor довольно странно ведёт себя на рынке видеоадаптеров. Одну серию устройств она продаёт в заводском исполнении, другую - игнорирует вообще, а третью наделяет сверхвозможностями. Видеокарта HD 7970, описание которой можно найти буквально во всех компьютерных журналах, заслуживает отдельного внимания покупателей, ведь речь идёт о водяном охлаждении. Сразу стоит отметить, что водоблок не бесплатный, и за устройство в сборе покупателю придётся заплатить порядка 25000 рублей (почти столько же стоит флагман на чипе AMD).

Как отмечают специалисты в своих отзывах, система водяного охлаждения, поставляемая с видеокартой, сильно напоминает водоблок известного бренда Zalman, да и принцип действия идентичный. Соответственно, вопросов по эффективности работы системы не должно возникнуть, как и со сборкой охлаждающего блока. Есть инструкция, набор комплектующих и даже ключ.
Естественно, такой монстр легко поддастся разгону, ведь эффективность водяного охлаждения значительно выше воздушного обдува. Графическое ядро стабильно работает на 1290 МГц, а видеопамять справляется с частотой 1750 МГц (7000 эффективная).
Двойной удар
Порадовала поклонников и компания XFX, представившая на рынке сразу две модификации чипсета HD 7970. Обзор недорогого устройства даже не следует начинать, ведь взяв заводскую видеокарту, производитель сделал фирменную гравировку на кожухе устройства и вывел продукт на рынок. Низкая цена без каких-либо доработок - совсем не похоже на серьёзный бренд.
А вот второе устройство XFX будет интересно любителям разгона, ведь производитель позволил себе полностью заменить систему питания на печатной плате видеоадаптера. Фирменные контроллеры силового блока управления фазами, микросхемы собственного производства и многие другие изменения значительно снизили энергопотребление видеокарты. С системой охлаждения новый велосипед изобретать не стали, снабдив устройство кулером, который ставится на топовый ускоритель R9.
Результатом всех нововведений стала эффективная работа видеоадаптера в разгоне на частоте графического ядра 1200 МГц. Память показывает стабильность на 1700 МГц. Великолепные показатели для устройства, температура которого удерживается в пределах 70 градусов по Цельсию.
В гонке за производительностью
Компания MSI представила на рынке свой продукт под названием HD 7970 Lightning. Главной особенностью данной видеокарты является фирменная система охлаждения. Производитель не стал заниматься доработкой печатной платы, доверившись полностью технологам AMD, а потратил всё своё время на создание эффективной системы отвода тепла.

Алюминиевое основание охватывает корпус печатной платы с двух сторон - решение довольно странное, ведь на обратной стороне устройства нет силовых элементов. По всему периметру видеокарты установлен алюминиевый радиатор с медными трубками, которые сводятся к контактной площадке графического ядра. В местах установки вентиляторов алюминиевые решётки немного срезаны по высоте, создавав небольшие углубления для монтажа кулеров (отдалённо напоминает Gainward Phantom). В результате разгона можно добиться стабильности работы графического чипа на частоте 1190 МГц, а памяти - 1650 Мгц.
В заключение
На рынке России представлено много продуктов, созданных на ядре HD 7970, но их эффективность разгона настолько мала, что нет смысла расписывать их достоинства. В обзоре представлены устройства, которые будут интересны покупателям, ориентирующимся при покупке либо на низкую стоимость, либо на большой потенциал для Золотая середина в последнее время выходит из моды.
В самом конце прошлого года компания AMD раскрыла исходный код своей новой GPU архитектуры, названной Southern Islands. Одним из первых воплощений этой инновации стала видеокарта SAPPHIRE HD 7970 3GB GDDR5.
Эта архитектура явилась продуктом некоторого спада в развитии технологии 28 нм и названа представителями AMD не иначе как революционной и призванной к 1.4x ускорению относительно предыдущего поколения. Помимо этого в SAPPHIRE HD 7970 мы получаем поддержку PCIe 3, 3 ГБ высокоскоростной памяти GDDR5, совместимость с DX 11.1, поддержку технологий Power Tune, Zero Core и Eyefinity 2.0, которая обрела новые функции и особенности. Новое ядро от AMD, называемое Graphics Core Next Tahiti – это шаг от VLIW дизайна к не VLIW SIMD движку, что означает более высокие показатели вычислительной производительности.




Это новое ядро обладает значительно возросшим числом транзисторов (4.31 миллиадра), 2048 потоковыми процессорами с 32 растровыми юнитами, 128 текстурными юнитами и 384-битной широкополосной шиной памяти, которая обеспечивает кратное увеличение мощности вычислений и полосы пропускания памяти. Все эти характеристики на бумаге выглядят более чем внушительно и должны вознести игровой опыт на новый уровень.
|
Характеристики SAPPHIRE HD 7970 |
|
| Выходы | 1 x Dual-Link DVI 1 x HDMI 1.4a 2 x Mini-DisplayPort DisplayPort 1.2 |
| GPU | Частота ядра 925 МГц Технология производства чипа 28 нм Количество потоковых процессоров — 2048 |
| Память | Объем — 3072 МБ Тип — 384-бит GDDR5 Эффективность — 5500 МГц |
| Размеры | 275(д)x115(ш)x36(в) мм |
| ПО | CD с драйверами SAPPHIRE TriXX Utility |
| Аксессуары | Кабель CrossFire™ Bridge Interconnect Кабель питания 8 PIN на 4 PIN Переходник Mini Display Port на HDMI Переходник Mini DP на SL-DVI Passive Кабель питания 6 PIN на 4 PIN Адаптер HDMI на SL-DVI HDMI 1.4a высокоскоростной кабель (1.8 метра) Переходник Mini DP на SL-DVI Active |
SAPPHIRE HD 7970: Тесты
Тест SAPPHIRE HD 7970 происходил в сравнении с другими устройствами этого же класса и состояло из комплекса игровых тестов и синтетического бенчмарка. Выбранные для сравнения карты номинально либо равны, либо номинально превосходят по производительности HD 7970, так что результаты испытаний в полной мере должно отразить реальные показатели.
Конфигурация и настройки системы не будут меняться в течение всех тестов. Видеокарты пройдут испытания сначала на штатной скорости, а затем в разогнанной конфигурации (описание процесса и результатов разгона HD 7970 приведено ниже) в целях оценки эффективности ускорения устройства. Для AMD карт использовался драйвер 11.12 Catalyst, а для карт на основе NVIDIA — 290.53.
Конфигурация тестируемой системы :
- Процессор : Core i7 2600K @ 4.4 ГГц 100 x 44
- Охлаждение CPU : Corsair Hydro Series H100
- Материнская карта : Gigabyte Z68AP-D3
- Память : Mushkin 991996 Redline PC3-17000 9-11-10-28 8 ГБ
- Видеокарта : Sapphire Radeon HD 7970
- Блок питания : Corsair AX1200
- Жесткий диск : 1 x Seagate 1 ТБ SATA
- Оптический привод : Lite-On Blu-Ray
- Операционная система : Windows 7 Professional 64-bit
Сравниваемые видеокарты :
- XFX HD 6970
- ASUS HD 6950
- ASUS GTX 580 Direct CU II
- ASUS GTX 570 Direct CU II
- Sapphire HD 6990
- ASUS GTX 590
Игровой тест: Metro 2033
Частично шутер от первого лица, частично хоррор — игра Metro 2033 построена на движке 4A Engine с поддержкой DirectX 11, NVIDIA PhysX и NVIDIA 3D Vision.
Настройки :
- DirectX 11
- 16x AF
- Глобальные настройки = высокие
- Physx = вкл




В игре Metro 2033 видеокарты SAPPHIRE HD 7970 показала очень сильные результаты на обоих разрешениях, как в штатном состоянии, так и в разогнанном.
Игровой тест: Battlefield 3

Battlefield 3 – шутер от первого лица, разработанный в EA Digital Illusions CE и использующий движок Frostbyte 2. Релиз этой игры состоялся 25 октября 2011. Она поддерживает DirectX 10 и 11.
Настройки :
- 4x AA в CP
- 16X AF в CP
- Игровые настройки = Высокие


В сравнении с предыдущим поколением устройств, построенных на Cayman, — картой HD 6970, имеющая в основе своей ядро Tahiti карта HD 7970 показала существенный прирост мощности в этой игре.
Игровой тест Dirt 3

Dirt 3 – третья игра из легендарной гоночной серии, разработанной Codemasters. Она построена на движке EGO 2.0. Релиз состоялся в мае 2011.
Настройки :
- 4x AA
- 16AF в CP
- Настройки = Ultra


В этой игре, выпускаемой, кстати, с маркером “AMD” на коробке, карта HD 7970 была на уровне GTX 580. Разгон больше помог GTX 580, нежели HD 7970.
Тестирование синтетическим бенчмарком 3DMark 11
3DMark 11 – последний бенчмарк Futuremark из серии 3DMark, приспособленный для тестирования систем с Microsoft DirectX 11. Эта программа состоит из шести тестов, четыре из которых предназначены для тестирования графики, один на моделирование физики и один комбинированный. Для тестирования на физической модели используется библиотека Bullet Physics. С бенчмарком поставляются два демо, оба они построены на тестах, но в отличии от тестов содержат базовое аудио.
Настройки :
- Настройки теста по умолчанию
- Начальный тест 1024 x 600
- Производительный тест 1280 x 720
- Экстремальный тест 1920 x 1080

По прохождении теста 3DMark11, результаты видеокарты SAPPHIRE HD 7970 оказались на более высоком уровне относительно GTX 580, как в штатной, так и в разогнанной конфигурациях.
В ходе температурных тестов было установлено, что SAPPHIRE HD 7970 как на штатных частотах, так и в разогнанном состоянии показала значения на 8 градусов ниже последнего поколения карт HD 6970, что является отличным для такой мощности устройства результатом.
На штатных и повышенных частотах технология Zero Core отлично сокращает энергопотребления в режиме ожидания. Под нагрузкой без увеличения вольтажа процессора общее энергопотребление карты заметно не возрастает.
Разгон
Из официальных релизов карточек от AMD, штатная скорость ядра которых превышает 1000 МГц, можно сделать вывод, что с новым Southern Islands Tahiti нас ждет прекрасная перспектива разгона. На самом деле 1000 МГц – это лишь отправная точка и похоже, что карта сможет выйти за рамки ограничений, установленных в Catalyst Control. Достижение 1125 МГц на ядре обеспечивается всего лишь перестановкой подаваемого на него напряжения посредством доступных из CC настроек. Выставкой подаваемого напряжения на память на ограничения CC вывели этот узел на скорость в 1575 МГц. Эти частоты свидетельствуют о том, что в запасе имеется как минимум еще 200 МГц как на ядрах GPU, так и на памяти GDDR5. Это очень хорошие показатели. Без подведения дополнительного напряжения температура на GPU значительно не повышалась. При ручном выведении скорости вращения вентилятора на 100%, температура разогнанной карты не превысила 57 градусов. Далее любому желающему придется подыскать утилиты (для BIOS или программные) для того, чтобы превысить ограничения CC и увидеть, на что же способна видеокарта на самом деле. Стоит отметить, что ускорение вентилятора на картах AMD всегда помогает удерживать рост температуры, но только за счет серьезного повышения уровня шума. В случае с SAPPHIRE RADEON HD 7970, AMD с помощью новой конструкции кулера улучшила показатели как охлаждения, так и шума.
Подведем итог нашего оверклокинга: 200 МГц – это 21% прирост на ядре и около 15% тактовой частоты памяти на первом этапе разгона позволяют говорить о светлом будущем видеокарты.
Отзывы: плюсы и минусы
Когда мы пытаемся понять, обеспечивает ли новый релиз нам все то, что мы от него хотели и ждали, то понимаем – новая видеокарта не только превосходит предыдущие поколения устройств, но и оставляет за бортом большинство прямых современных конкурентов. Отзыв о SAPPHIRE HD 7970 — видеокарта чрезвычайно убедительна. Она легко демонстрирует производительность, на уровень превышающую показатели построенной на Northern Islands Cayman карты HD 6970, а также показатели Nvidia GTX 580 практически во всех тестах. При этом уже на штатных тактовых частотах впечатляет даже игровая производительность, а пространство, предоставляемое устройством для разгона, открывает прямо-таки захватывающие перспективы. Нам удалось легко повысить скорость ядра GPU и памяти до пределов AMD Catalyst Control Center и установить их на отметки 1125 МГц на ядре и 1575 МГц на памяти – на обоих узлах без усилий мы получили прирост в 200 МГц. Такая дополнительная мощность позволяет использовать одну карту для игры по технологии Eyefinity на разрешениях до 5760 x 1080. Новая архитектура карты SAPPHIRE HD 7970 поддерживает новую версию технологии Eyefinity — 2.0, которая предлагает ряд усовершенствований, включая индивидуальные медиаканалы для каждого выхода, новую конфигурацию — 5×1 монитор и множество других.
Стоит отметить улучшенную производительность системы охлаждения AMD. И на штатных частотах, и в разогнанном состоянии температура HD 7970 была ниже температуры HD 6970 примерно на 4 градуса Цельсия на штатных частотах в режиме ожидания и на 8 градусах в остальных режимах.
Хотя энергопотребление HD 7970 под нагрузкой было выше, чем HD 6970, в режиме ожидания технология AMD ZeroCore помогала снизить этот показатель примерно в два раза.
Плата за все вышеописанные прелести HD 7970 составляет примерно $550, и некоторых покупателей это может неприятно удивить. Но за эти деньги в распоряжение вам попадает действительно мощная карта, намного превосходящая своих конкурентов, включая HD 6970. Если поискать, то за цену, примерно на $50 дешевле указанной можно купить две HD 6970 и получить производительность на уровне HD 6990+, заплатив сверх денег цену высокого уровня шума и энергопотребления. Покупая же SAPPHIRE HD 7970 3GB GDDR5, вы получаете самую быструю на сегодня видеокарту с одним GPU, которая легко и без тормозов потянет любую современную игру! AMD и партнеры снова сделали великолепный продукт!
Плюсы:
- Быстрейшая видеокарта с одним GPU
- Прекрасные возможности разгона
- Высокая производительность
- Игра через Eyefinity
- Новая архитектура
- Технология Zero Core
- Сокращение шума
Минусы:
- Вентилятор по-прежнему громкий на 100% скорости
Просмотры: (1943)
- Часть 2 — Практическое знакомство
- Часть 3 — Результаты игровых тестов (производительность)
В этой части, как обычно, мы изучим саму видеокарту, а также познакомимся с результатами синтетических тестов.
Плата
|
|
| AMD Radeon HD 7970 3072 МБ 384-битной GDDR5 PCI-E | |
|---|---|
|
Карта имеет 3072 МБ памяти GDDR5 SDRAM, размещенной в 12 микросхемах на лицевой сторонe PCB. За неимением собственных синтетических тестов DirectX 11 мы снова воспользовались примерами из пакетов SDK Microsoft и AMD и демонстрационной программой Nvidia. Во-первых, это HDRToneMappingCS11.exe и NBodyGravityCS11.exe из комплекта DirectX SDK (February 2010) . Также мы взяли приложения обоих производителей: Nvidia и AMD. Из ATI Radeon SDK были взяты примеры DetailTessellation11 и PNTriangles11 (они также есть и в DirectX SDK). Дополнительно использовалась демонстрационная программа компании Nvidia — Realistic Water Terrain , также известная как Island11 (автор — Тимофей Чеблоков, известный специалист по 3D-графике). Синтетические тесты проводились на следующих видеокартах:
Для сравнения результатов новейшей видеокарты Radeon HD 7970 именно эти модели были выбраны по разным причинам. Radeon HD 6970 была взята, как прямой предшественник топового сегмента, HD 6990 — как сильнейшее (пусть и двухчиповое) решение на GPU предыдущей архитектуры, HD 5870 мы добавили, чтобы оценить прирост между двумя разными обновлениями архитектур и как GPU ровно вдвое меньшей сложности, чем Tahiti. Выбранные решения Nvidia взяты потому, что Geforce GTX 580 — быстрейшая одночиповая модель этой компании, основанная на GPU последнего поколения. Хотя она не является конкурентом представленной видеокарты AMD по цене, её результаты интересны как максимальные для нынешних одночиповых решений Nvidia. А двухчиповая GTX 590 является экстремальным вариантом этой компании с более высокой ценой. В тестах DirectX 11 мы использовали ещё и Geforce GTX 560 Ti, которая нужна для того, чтобы оценить увеличенную геометрическую производительность нового графического процессора AMD. Direct3D 9: тесты Pixel FillingВ этом тесте определяется пиковая производительность выборки текстур (texel rate) в режиме FFP для разного числа текстур, накладываемых на один пиксель:
В нашем устаревшем тесте фильтрации 32-битных текстур из RightMark большинство видеокарт показывает цифры, далёкие от теоретически возможных. Вот и результаты текстурной синтетики в случае видеоплаты Radeon HD 7970 не дотянули до пикового значения, поэтому мы ещё раз рассмотрим скорость текстурирования по цифрам из теста 3DMark Vantage, в котором всегда получаются более реалистичные цифры. У нас же получилось, что HD 7970 выбирает лишь до 80 текселей за такт из 32-битных текстур при билинейной фильтрации, что значительно ниже теоретической цифры в 128 отфильтрованных текселей. В остальном, всё получилось предсказуемо — все платы производства AMD показали более высокую производительность и опережают видеокарты компании Nvidia. Ведь даже топовая одночиповая Geforce GTX 580 имеет лишь 64 TMU и поэтому сильно уступает модели на базе чипа Tahiti, имеющем 128 TMU, работающих на более высокой частоте. Поэтому и разница более чем двукратная. Ну а двухчиповый GTX 590 в этом тесте показывает явно неадекватный результат. Вариант платы на двух GPU от компании AMD также явно некорректно работает в нашем тесте, ведь HD 7970 обгоняет почти всегда даже его. Ну а своего предшественника новая модель обогнала примерно на 30%, что чуть хуже теоретически возможного значений. Впрочем, в случаях с малым количеством текстур, когда больше всего сказывается пропускная способность памяти, результат ещё ниже — порядка 25%. Рассмотрим эти же результаты в тесте филлрейта:
Цифры показывают скорость заполнения, и в них мы видим всё то же самое, разве что с учетом количества записанных в буфер кадра пикселей. Максимальный результат почти всегда остаётся за новой топовой видеокартой из семейства Radeon HD 7900. Она имеет рекордное количество TMU, работающих на более высокой частоте и более эффективных в нашем синтетическом тесте. Переходим к текстам простых пиксельных шейдеров. Direct3D 9: тесты Pixel ShadersПервая группа пиксельных шейдеров, которую мы рассматриваем, очень проста для современных видеочипов, она включает в себя различные версии пиксельных программ сравнительно низкой сложности: 1.1, 1.4 и 2.0, встречающихся в старых играх.
Эти тесты слишком просты для современных GPU и в основном ограничены производительностью текстурирования и иногда филлрейтом. Поэтому они показывают далеко не все возможности современных видеочипов, но интересны с точки зрения устаревших игровых приложений. В двух самых простых тестах новый Radeon HD 7970 почти догнал даже двухчиповый HD 6990, но в более сложных занял позицию между HD 6990 и HD 6970. Интересно, как отличается поведение тестов на GPU разных архитектур. И тут Tahiti несколько ближе к GF110, чем к предшественнику. Естественно, не по абсолютным цифрам, разница в них весьма велика — от полутора до двух раз. Производительность в других тестах ограничена по большей части скоростью текстурных модулей и филлрейтом, поэтому новый Radeon HD 7970 получился быстрее предшествующего HD 6970 примерно на 30-40%, что соответствует теории. Все платы AMD опережают обе топовые модели Geforce, разве что в сравнении HD 5870 и GTX 590 всё не так однозначно. В неудачах Nvidia в этих тестах явно виноват недостаток скорости текстурирования. Но даже пиксельный шейдер освещения тремя источниками по Фонгу, больше зависящий от математической производительности GPU, при запуске на GF110 сильно уступает и Cayman и уж тем более Tahiti. Посмотрим на результаты более сложных пиксельных программ промежуточных версий:
Вот и в этот раз получилось примерно то же самое, HD 7970 расположился примерно между одночиповой и двухчиповой моделями на базе Cayman из серии HD 6900. Тест Cook-Torrance более интенсивен вычислительно, и разница в нём примерно соответствует разнице в количестве ALU и их частоте. Поэтому данный тест лучше подходит для архитектуры AMD, чипы которой имеют большее количество математических блоков, и Tahiti тут не исключение. Интересно, что в этом тесте HD 5870 обгоняет HD 6970, и похоже, что так получилось из-за худшей эффективности исполнения этого шейдера на более новом чипе с VLIW4 архитектурой. Так что, хотя новый Radeon HD 7970 и обошёл HD 6970, он оказался быстрее HD 5870 в этом тесте лишь на 20%. Во втором, сильнее зависящем от скорости текстурирования, тесте процедурной визуализации воды «Water» используется зависимая выборка из текстур больших уровней вложенности, и видеокарты в нём располагаются по скорости текстурирования, с поправкой на разную эффективность использования TMU. В этом тесте у решений компании AMD всегда всё прекрасно, и HD 7970 обеспечивает очень хороший результат, хотя и хуже, чем у двухчиповой HD 6990, но гораздо лучший, чем у предшественника на Cayman. Топовая одночиповая плата Nvidia отстала более чем в 2,5 раза! Direct3D 9: тесты пиксельных шейдеров Pixel Shaders 2.0Эти тесты пиксельных шейдеров DirectX 9 сложнее предыдущих, они близки к тому, что мы сейчас видим в мультиплатформенных играх, и делятся на две категории. Начнем с более простых шейдеров версии 2.0:
Существует два варианта этих шейдеров: с ориентацией на математические вычисления и с предпочтением выборки значений из текстур. Рассмотрим математически интенсивные варианты, более перспективные с точки зрения будущих приложений:
Это — универсальные тесты, зависящие и от скорости блоков ALU, и от скорости текстурирования, в них важен общий баланс чипа, а также эффективность исполнения сложных программ. И производительность новой видеокарты AMD в тесте «Frozen Glass» оказалась не просто хорошей, но отличной! Вот что значит повышенная эффективность нового GPU. Radeon HD 7970 в первом тесте оказалась заметно быстрее даже чем двухчиповая HD 6990. А даже двухчиповая плата Nvidia осталась далеко позади, не говоря уже о Geforce GTX 580. Вот во втором тесте «Parallax Mapping» решения Nvidia чувствуют себя немного лучше, и GTX 580 почти достаёт HD 6970. А вот до представленной сегодня HD 7970 очень далеко — новинка AMD опережает лучшую плату Nvidia на 80%, что явно говорит о влиянии и математических расчётов и скорости текстурирования. Интересно, что совсем старая HD 5870 снова быстрее, чем HD 6970. Да и новая HD 7970 обогнала предшественницу на 60%, что явно не оправдать сухими теоретическими цифрами. Тут сказалась заметно большая эффективность скалярной архитектуры, по сравнению с VLIW. Впрочем, в случае видеокарт AMD всё очень сложно из-за PowerTune. Ведь синтетические тесты очень сильно «грузят» GPU расчётами и энергопотребление плат с поддержкой PowerTune в синтетике вполне может выходить за рамки выставленного ограничения. Следовательно, может снижаться и тактовая частота GPU, а вместе с ней и результаты будут показаны ниже, чем ожидалось. Рассмотрим эти же тесты в модификации с предпочтением выборок из текстур математическим вычислениям:
Для обеих видеоплат Nvidia ситуация стала ещё печальнее, так как со скоростью текстурирования у всех современных чипов AMD всё намного лучше, и в этих тестах они лишь наращивают своё бесспорное преимущество. Даже двухчиповая GTX 590 не может соперничать с одночиповым HD 6970 в обоих тестах с упором на текстурирование, не говоря о GTX 580. Ну а представленная сегодня плата из семейства Radeon HD 7900 оказалась быстрейшей среди одночиповых карт, уступив только HD 6990. Разница между HD 7970 и HD 6970 оказалась равна 26-28%, что хорошо объяснимо теоретически, так как разница в скорости текстурирования у новинки немногим больше. Но это были устаревшие задачи, в основном с упором в текстурирование, и иногда в филлрейт. Далее мы рассмотрим результаты ещё двух тестов пиксельных шейдеров — но уже версии 3.0, самых сложных из наших тестов пиксельных шейдеров для Direct3D 9 API. Они наиболее показательны с точки зрения современных игр на ПК, среди которых много мультиплатформенных. Тесты отличаются тем, что сильно нагружают и ALU, и текстурные модули, обе шейдерные программы сложны и длинны, и включают большое количество ветвлений:
В самых сложных DX9-тестах из RightMark видеокарты производства Nvidia всегда выступают очень сильно, в противоположность всем предыдущим испытаниям нашего обзора. Эти тесты не ограничены производительностью текстурных выборок, а зависят скорее от эффективности исполнения шейдерного кода. И ранее Radeon HD 6970 явно улучшил позиции AMD в данном тесте, увеличив эффективность при переходе от архитектуры VLIW5 к VLIW4. Ну а сегодня мы увидели очередной скачок в производительности решений компании, Radeon HD 7970 поднял их на недосягаемый уровень — новая одночиповая видеоплата обошла даже двухчиповый HD 6990 в обоих тестах! Эти задачи — отличный пример улучшения реальной производительности сложных вычислений при переходе от VLIW к скалярному исполнению. Итак, в тестах сложных пиксельных шейдеров версии 3.0 новая топовая видеокарта AMD смогла не только догнать конкурентов, но и опередить со значительным запасом, чего не было очень давно. Скорость в обоих тестах PS 3.0 слабо зависит от ПСП и текстурирования, зато код отличается сложностью, с чем очень неплохо справляется и архитектура Nvidia и новейшая скалярная архитектура AMD. Эти тесты одни из первых, где мы отмечаем явное улучшение эффективности и наибольшую положительную разницу между предыдущей и новейшей архитектурами компании AMD по скорости. Но приведём цифры, чтобы не быть голословными. Представленная новинка Radeon HD 7970 быстрее предшественницы более чем вдвое, и на 60-70% быстрее Geforce GTX 580, о чём совсем недавно мы даже и подумать бы не решились. Ведь решения Nvidia всегда были неоспоримыми лидерами в этой паре тестовых задач, но видеокарты на Cayman смогли к ним приблизиться, а быстрейший из Tahiti наконец-то опередил конкурента. Direct3D 10: тесты пиксельных шейдеров PS 4.0 (текстурирование, циклы)Во вторую версию RightMark3D вошли два знакомых теста PS 3.0 под Direct3D 9, которые были переписаны под DirectX 10, а также ещё два новых теста. В первую пару добавились возможности включения самозатенения и шейдерного суперсэмплинга, что дополнительно увеличивает нагрузку на видеочипы. Данные тесты измеряют производительность выполнения пиксельных шейдеров с циклами при большом количестве текстурных выборок (в самом тяжелом режиме до нескольких сотен выборок на пиксель) и сравнительно небольшой загрузке ALU. Иными словами, в них измеряется скорость текстурных выборок и эффективность ветвлений в пиксельном шейдере. Первым тестом пиксельных шейдеров будет Fur. При самых низких настройках в нём используется от 15 до 30 текстурных выборок из карты высот и две выборки из основной текстуры. Режим Effect detail — «High» увеличивает количество выборок до 40—80, включение «шейдерного» суперсэмплинга — до 60—120 выборок, а режим «High» совместно с SSAA отличается максимальной «тяжестью» — от 160 до 320 выборок из карты высот. Проверим сначала режимы без включенного суперсэмплинга, они относительно просты, и соотношение результатов в режимах «Low» и «High» должно быть примерно одинаковым. Производительность в этом тесте зависит от количества и эффективности блоков TMU, и от эффективности выполнения сложных программ. В варианте без суперсэмплинга дополнительное влияние на производительность оказывает эффективный филлрейт (производительность ROP) и пропускная способность памяти. Результаты при детализации уровня «High» получаются примерно в полтора раза ниже, чем при «Low», как и должно быть по теории, но для быстрейших решений разница несколько ниже. Ранее в тестах процедурной визуализации меха с большим количеством текстурных выборок решения Nvidia были заметно сильнее, но начиная с предыдущего поколения компании AMD, разница начала сокращаться. Что же получилось у Radeon HD 7970? Отличный результат — новинка AMD снова оказалась быстрее двухчиповой платы предыдущего поколения, а одночиповая HD 6970 отстала вдвое, что явно говорит об увеличении эффективности новой архитектуры Southern Islands. Да и решения компании Nvidia остались позади, даже двухчиповая GTX 590 уступила представленной сегодня топовой модели Radeon HD 7970. Посмотрим на результат этого же теста, но с включенным «шейдерным» суперсэмплингом, увеличивающим работу в четыре раза: возможно, в такой ситуации что-то изменится, и ПСП с филлрейтом будут влиять меньше: Включение суперсэмплинга увеличивает теоретическую нагрузку в четыре раза, и результаты решений Nvidia всегда падают, по сравнению с показателями видеокарт AMD. Теперь разница в эффективности выполнения данной задачи ещё более очевидна, и новая модель HD 7970 быстрее HD 6970 в 2,5 раза! Примерно столько же новинке уступила и Geforce GTX 580. Вполне естественно, что даже HD 6990 осталась далеко позади, а новая плата укрепила лидерство, да какое… Второй шейдерный DX10-тест измеряет производительность исполнения сложных пиксельных шейдеров с циклами при большом количестве текстурных выборок и называется Steep Parallax Mapping. При низких настройках он использует от 10 до 50 текстурных выборок из карты высот и три выборки из основных текстур. При включении тяжелого режима с самозатенением число выборок возрастает в два раза, а суперсэмплинг увеличивает это число в четыре раза. Наиболее сложный тестовый режим с суперсэмплингом и самозатенением выбирает от 80 до 400 текстурных значений, то есть в восемь раз больше по сравнению с простым режимом. Проверяем сначала простые варианты без суперсэмплинга: Второй пиксель-шейдерный тест Direct3D 10 несколько интереснее с практической точки зрения, так как разновидности parallax mapping широко применяются в играх, а тяжелые варианты, вроде нашего steep parallax mapping используются во многих проектах, например в играх серий Crysis и Lost Planet. Кроме того, в нашем тесте, помимо суперсэмплинга, можно включить самозатенение, увеличивающее нагрузку на видеочип примерно в два раза, такой режим называется «High». Эта диаграмма похожа на предыдущую без включения SSAA, но позиции Nvidia ещё немного ослабли, да и Radeon HD 6990 почти догнала представленную сегодня модель. В обновленном D3D10-варианте теста без суперсэмплинга HD 7970 показывает отличный результат, значительно опережая и HD 6970 и GTX 580 и даже GTX 590. Лидерство делят HD 7970 и HD 6990, а две старые видеокарты производства AMD показывают схожие результаты и сильно (в два и более раза медленнее новой модели) отстают. Посмотрим, что изменит включение суперсэмплинга, он может вызвать сильное падение скорости на платах Nvidia. При включении суперсэмплинга и самозатенения, задача получается ещё более тяжёлой, совместное включение сразу двух опций увеличивает нагрузку на карты почти в восемь раз, вызывая большое падение производительности. Разница между скоростными показателями протестированных видеокарт изменилась, включение суперсэмплинга сказывается, как и в предыдущем случае — карты производства AMD улучшили свои показатели относительно решений Nvidia. И теперь Radeon HD 7970 снова становится единоличным лидером сравнения, показывая результаты выше, чем у HD 6990. Более старые одночиповые платы компании далеко позади, вместе с ними и Geforce GTX 580. И лишь более дорогие двухчиповые варианты от AMD и Nvidia способны хоть как-то приблизиться к свежей видеоплате. В общем, по двум шейдерным D3D10 тестам можно сделать вывод, что новая архитектура AMD и её представитель на чипе Tahiti великолепно справляется с «шейдерными» задачами, даже лучше традиционно сильных в них конкурентов от Nvidia. Direct3D 10: тесты пиксельных шейдеров PS 4.0 (вычисления)Следующая пара тестов пиксельных шейдеров содержит минимальное количество текстурных выборок для снижения влияния производительности блоков TMU. В них используется большое количество арифметических операций, и измеряют они именно математическую производительность видеочипов, скорость выполнения арифметических инструкций в пиксельном шейдере. Первый математический тест — Mineral. Это тест сложного процедурного текстурирования, в котором используются лишь две выборки из текстурных данных и 65 инструкций типа sin и cos. Результаты предельных математических тестов обычно соответствуют разнице в частотах и количестве исполнительных блоков, но с некоторым влиянием разной эффективности их использования. Все последние архитектуры AMD в таких случаях имеют подавляющее преимущество перед конкурирующими видеокартами Nvidia, и это объясняет результаты тестов, в которых решения AMD снова оказываются значительно более производительными. Решения расположились примерно соответственно теории, но за некоторыми исключениями. На практике открылись некоторые нюансы, связанные с различной эффективностью. Теоретически, Geforce GTX 580 должна быть более чем вдвое (2,4 раза) медленнее, чем новая модель Radeon HD 7970, на практике же разница составляет лишь 80%, что значительно меньше. Да и при сравнении с HD 6970 возникают вопросы оптимизации новой архитектуры и драйверов для неё к этому тесту. При теоретическом превосходстве по вычислениям в 40%, новая плата AMD лишь на 28% быстрее предыдущей — HD 6970, а ещё меньше дистанция между ней и совсем старой HD 5870, основанной на VLIW5-архитектуре. То ли тест действительно лучше подходит для VLIW (особенно для VLIW5), то ли виноваты ещё сырые драйверы. Есть и ещё одно объяснение — возможно, на результаты плат HD 7970 HD 6970 в этом тесте повлияла технология PowerTune, снизившая частоты при достижении предела энергопотребления. Впрочем, всё это мало что меняет при сравнении с конкурентом, ведь даже дорогущая двухчиповая плата Geforce GTX 590 лишь достигла уровня HD 6970 и HD 5870. А уж одночиповая GTX 580 так и вовсе далеко позади. Рассмотрим второй тест шейдерных вычислений, который носит название Fire. Он тяжелее для ALU, и текстурная выборка в нём только одна, а количество инструкций типа sin и cos увеличено вдвое, до 130. Посмотрим, что изменилось при увеличении нагрузки: Мы видим почти идентичную предыдущей диаграмму, за исключением абсолютных цифр. В этот раз все GPU остались примерно на тех же позициях, ну разве что видеоплаты на базе Cayman и Cypress поменялись местами — теперь чуть-чуть быстрее более новая модель, но совсем незначительно. Хотя строгого соответствия теоретическим цифрам пиковой производительности всё так же нет, но их результаты всё-таки близки к сухой теории. Разница между HD 7990 и HD 6970 немного увеличилась. В остальном, мы не нашли на графике ничего нового. Скорость рендеринга в этом тесте ограничена исключительно производительностью шейдерных блоков и их эффективностью, поэтому двухчиповая HD 6990 снова стала явным лидером, а за ней на приличном отдалении следует сегодняшняя новинка от AMD. Обе платы Geforce уступают даже устаревшей модели из семейства Radeon HD 5800, но и в этот раз преимущество решений AMD остаётся несколько меньшим, чем при сравнении теоретических цифр, и это снова говорит о худшей оптимизации или влиянии PowerTune. Direct3D 10: тесты геометрических шейдеровВ пакете RightMark3D 2.0 есть два теста скорости геометрических шейдеров, первый вариант носит название «Galaxy», техника аналогична «point sprites» из предыдущих версий Direct3D. В нем анимируется система частиц на GPU, геометрический шейдер из каждой точки создает четыре вершины, образующие частицу. Аналогичные алгоритмы должны получить широкое использование в будущих играх под DirectX 10. Изменение балансировки в тестах геометрических шейдеров не влияет на конечный результат рендеринга, итоговая картинка всегда абсолютно одинакова, изменяются лишь способы обработки сцены. Параметр «GS load» определяет, в каком из шейдеров производятся вычисления — в вершинном или геометрическом. Количество вычислений всегда одинаково. Рассмотрим первый вариант теста «Galaxy», с вычислениями в вершинном шейдере, для трёх уровней геометрической сложности: Соотношение скоростей при разной геометрической сложности сцен примерно одинаково для всех решений, производительность соответствует количеству точек, с каждым шагом падение FPS составляет около двух раз. Задача для современных видеокарт не слишком сложная, и производительность ограничена в основном скоростью обработки геометрии, но ещё и пропускной способностью памяти/филлрейтом (в рамках решений одного производителя). В этом тесте должны были проявиться улучшенные возможности Southern Islands по обработке геометрии, вот они и проявились. Новая видеокарта AMD действительно гораздо быстрее выполняет геометрические расчёты, по сравнению со всеми предыдущими решениями компании. Хотя AMD дала цифры прироста до 4 раз, но в этом тесте геометрическая производительность выросла примерно в 1,5-2 раза. В итоге, одночиповая видеокарта оказалась примерно на том же уровне, что и двухчиповая модель Radeon HD 6990 на GPU предыдущего поколения. Столь значительное улучшение привело к тому, что Tahiti практически догнала топовую видеокарту Nvidia, хотя выполнение геометрических шейдеров у той в некоторых условиях должно быть ещё эффективнее. Ранее видеокарты Nvidia справлялись с работой примерно вдвое быстрее аналогичных видеокарт конкурента, а теперь разницы совсем нет. Посмотрим, как изменится ситуация при переносе части вычислений в геометрический шейдер: При изменении нагрузки в этом тесте цифры почти не изменились для решений Nvidia и большинства плат AMD. Лишь новая видеокарта из семейства HD 7900 в данном тесте слабо отреагировала на изменение параметра GS load, отвечающего за перенос части вычислений в геометрический шейдер. Поэтому плата показала результат чуть выше, чем на предыдущей диаграмме. Посмотрим, что изменится в следующем тесте, который предполагает большую нагрузку именно на геометрические шейдеры. «Hyperlight» — это второй тест геометрических шейдеров, демонстрирующий использование сразу нескольких техник: instancing, stream output, buffer load. В нем используется динамическое создание геометрии при помощи отрисовки в два буфера, а также новая возможность Direct3D 10 — stream output. Первый шейдер генерирует направление лучей, скорость и направление их роста, эти данные помещаются в буфер, который используется вторым шейдером для отрисовки. По каждой точке луча строятся 14 вершин по кругу, всего до миллиона выходных точек. Новый тип шейдерных программ используется для генерации «лучей», а с параметром «GS load», выставленным в «Heavy» — ещё и для их отрисовки. То есть в режиме «Balanced» геометрические шейдеры используются только для создания и «роста» лучей, вывод осуществляется при помощи «instancing», а в режиме «Heavy» выводом также занимается геометрический шейдер. Сначала рассматриваем лёгкий режим: Относительные результаты в разных режимах снова примерно соответствуют изменению нагрузки: во всех случаях производительность неплохо масштабируется и близка к теоретическим параметрам, по которым каждый следующий уровень «Polygon count» должен быть менее чем в два раза медленней. В этом тесте скорость рендеринга должна быть ограничена геометрической производительностью, и новая архитектура от компании AMD показывает себя просто отлично, даже немного обгоняя конкурента в лице Geforce GTX 580! Обе двухчиповые платы тут показали некорректные результаты, поэтому с ними сравнения не получится. Зато HD 7970 на 40-50% быстрее своей предшественницы — модели HD 6970, что явно объясняется архитектурными изменениями в GPU. Отличные результаты карты на Tahiti явно свидетельствуют о проведённой оптимизаций в блоках обработки геометрических данных в новом чипе. Цифры должны сильно измениться на следующей диаграмме, в тесте с более активным использованием геометрических шейдеров. Также будет интересно сравнить друг с другом результаты, полученные в режимах «Balanced» и «Heavy». А вот тут рекорда у Radeon HD 7970 не получилось, всё-таки разница между чипами AMD с традиционным графическим конвейером (в т. ч. и Cayman с Tahiti с двумя растеризаторами) и чипами с архитектурой Fermi, имеющей распараллеленную обработку геометрии, хорошо заметна. И результаты Geforce GTX 580, имеющей в своей основе чип GF110, хороши настолько, что она обгоняет лучшее из решений компании AMD (а это анонсированная сегодня модель) на 35-40%. Хотя возможности новенького топового чипа AMD по обработке геометрии и скорости исполнения геометрических шейдеров явно выросли по сравнению с предыдущими видеокартами компании, и первое решение на чипе Tahiti показывают в этих тестах результаты на 22-28% выше, чем решения на базе Cayman. Вероятно, инженеры AMD решили, что такой оптимизации блоков установки треугольников и обработки геометрии будет вполне достаточно. Direct3D 10: скорость выборки текстур из вершинных шейдеровВ тестах «Vertex Texture Fetch» измеряется скорость большого количества текстурных выборок из вершинного шейдера. Тесты схожи по сути, так что соотношение между результатами карт в тестах «Earth» и «Waves» должно быть примерно одинаковым. В обоих тестах используется displacement mapping на основании данных текстурных выборок, единственное существенное отличие состоит в том, что в тесте «Waves» используются условные переходы, а в «Earth» — нет. Рассмотрим первый тест «Earth», сначала в режиме «Effect detail Low»: Предыдущие исследования показали, что на результаты этого теста влияет сразу многое: и скорость текстурирования и пропускная способность памяти. И результаты видеокарт часто ограничены некоей преградой — посмотрите хотя бы на сравнение двухчиповой GTX 590 и одночипового аналога — между ними почти нет разницы. Хотя HD 6990 вдвое быстрее HD 6970. Да и новая плата AMD из семейства Radeon HD 7970 показала очень хорошие результаты, почти догнав лидирующую HD 6990. Что касается одночиповых конкурентов, то она лучшая во всех трёх режимах. Преимущество над HD 6970 составило от 25% до 75%, в зависимости от режима. Посмотрим на производительность в этом же тесте с увеличенным количеством текстурных выборок: А вот в этот раз взаимное расположение карт на диаграмме заметно изменилось, и особенно это касается тяжёлого режима. При малом количестве полигонов скорость рендеринга в этом тесте упирается в ПСП, поэтому платы AMD и были так сильны на предыдущей диаграмме. А вот в тяжёлых режимах разница между одночиповой картой Nvidia и новинкой AMD сократилась, и они соперничают между собой в довольно плотной борьбе. Старшая двухчиповая видеокарта семейства Radeon HD 6900 обгоняет все остальные решения и является лучшей в сравнении, хотя в тяжёлом режиме к ней подбирается и Geforce GTX 590. Новая же одночиповая HD 7970 выигрывает у предшественницы снова до 70%, что может говорить о сильном влиянии ПСП. Рассмотрим результаты второго теста текстурных выборок из вершинных шейдеров. Тест «Waves» отличается меньшим количеством выборок, зато в нём используются условные переходы. Количество билинейных текстурных выборок в данном случае до 14 («Effect detail Low») или до 24 («Effect detail High») на каждую вершину. Сложность геометрии изменяется аналогично предыдущему тесту. Результаты во втором тесте вершинного текстурирования «Waves» абсолютно не похожи на то, что мы видели на предыдущих диаграммах. В этом тесте видеокарты AMD и Nvidia, кроме HD 6990 и HD 7970, показывают очень близкие результаты, что снова можно списать на ограничение пропускной способностью видеопамяти, так как этот показатель у всех представленных видеокарт близок. А вот новая модель из семейства Southern Islands смогла выделиться, в сложных условиях сравнения почти догнав двухчиповую HD 6990, которая стала лучшей среди всех видеокарт. Разница между картами на базе графических процессоров Cayman и Tahiti снова составила 25-70% в пользу более нового решения. Рассмотрим второй вариант этого же теста: И тут произошли изменения, аналогичные тем, что мы видели ранее — видеокарты Nvidia «просели» только в лёгком режиме, а большинство решений AMD — сразу во всех. Впрочем, это не позволило платам калифорнийской компании догнать новинку семейства Radeon 7900. Которая, кстати, обогнала всех в среднем и тяжёлом режимах, уступив двухчиповой HD 6990 только один раз. В режиме с малым количеством полигонов разница между решениями не такая большая, а вот в среднем и тяжёлом старые решения AMD уступают, затем идут платы Nvidia (двухчиповая лишь немного быстрее одночиповой GTX 580), HD 6990 и HD 7970. Анонсированная сегодня плата семейства HD 7900 в тестах вершинных выборок показала себя отлично, с запасом обогнав и конкурирующие видеокарты Nvidia и предшественников от того же производителя. 3DMark Vantage: тесты FeatureКак всегда, синтетические тесты из пакета 3DMark Vantage могут показать нам что-то, что мы ранее упустили. Тесты Feature этого тестового пакета обладают поддержкой DirectX 10 и интересны тем, что отличаются от наших. При анализе результатов новой видеокарты Radeon HD 7970 в этом пакете мы сможем сделать какие-то новые и полезные выводы, ускользнувшие от нас в тестах семейства RightMark. Feature Test 1: Texture FillПервый тест — тест скорости текстурных выборок. Используется заполнение прямоугольника значениями, считываемыми из маленькой текстуры с использованием многочисленных текстурных координат, которые изменяются каждый кадр. Хотя тест компании Futuremark всё так же не показывает теоретически возможного уровня скорости текстурных выборок, но всё же эффективность видеокарт и AMD и Nvidia в нём заметно выше, чем в нашем из RightMark. Поэтому в данном текстурном тесте получается несколько иное соотношение результатов, которое ближе к истине. Первая видеокарта из нового семейства компании AMD показывает результат, близкий к соответствующему теоретическому параметру, и она справляется с работой эффективнее предыдущего поколения. Radeon HD 7970 опережает HD 6970 более чем на 50%, хотя по теории разница составляет лишь 40%. Вероятнее всего, текстурные модули Tahiti используются эффективнее из-за улучшений в системе памяти и кэширования, что и вызвало повышенный результат. Конечно, новая одночиповая модель не дотянула до лидера — двухчиповой HD 6990, но это и не ожидалось. И всё же, хорошо видно, что текстурная производительность графического чипа Tahiti заметно выросла по сравнению с Cayman. Ну а GTX 580 проигрывает новинке по скорости текстурирования целых 2,3 раза. Даже двухчиповая карта Nvidia догоняет лишь HD 6970. Feature Test 2: Color FillЭто тест скорости заполнения. Используется очень простой пиксельный шейдер, не ограничивающий производительность. Интерполированное значение цвета записывается во внеэкранный буфер (render target) с использованием альфа-блендинга. Используется 16-битный внеэкранный буфер формата FP16, наиболее часто используемый в играх, применяющих HDR-рендеринг, поэтому такой тест является вполне своевременным. Ситуация в тесте производительности блоков ROP серьёзно отличается от теста текстурирования. Цифры этого подтеста из 3DMark Vantage показывают производительность блоков ROP, но с влиянием величины пропускной способности видеопамяти (т. н. «эффективный филлрейт»). И тут новая модель HD 7970 показывает отличный результат, отстав лишь от двух топовых видеокарт AMD и Nvidia из предыдущих поколений, имеющих по два GPU на борту. А что же с эффективностью использования блоков ROP, которой хвалились AMD? Действительно, лишь 32 блока ROP в новом чипе Tahiti совсем не ограничивают скорость рендеринга даже в специализированном тесте. И мы отмечаем несколько бо́льшую эффективность блоков ROP и более высокую скорость заполнения у новой видеокарты компании AMD по сравнению со старыми моделями. Разница между HD 7970 и HD 6970 более чем 50%, что явно говорит о большем влиянии уже ПСП, а не чистой производительности блоков ROP. Что касается сравнения с Nvidia, то и тут разница по скорости (35%) соответствует теоретической разнице в ПСП (36%), а не чистой скорости блоков ROP. Получается, что 32 таких блока в Cayman просто были лишними и их возможности никогда не использовались полностью. Feature Test 3: Parallax Occlusion MappingОдин из самых интересных feature-тестов, так как подобная техника уже используется в играх. В нём рисуется один четырехугольник (точнее, два треугольника) с применением специальной техники Parallax Occlusion Mapping, имитирующей сложную геометрию. Используются довольно ресурсоёмкие операции по трассировке лучей и карта глубины большого разрешения. Также эта поверхность затеняется при помощи тяжёлого алгоритма Strauss. Это тест очень сложного и тяжелого для видеочипа пиксельного шейдера, содержащего многочисленные текстурные выборки при трассировке лучей, динамические ветвления и сложные расчёты освещения по Strauss. Этот тест отличается от других подобных тем, что результаты в нём зависят не исключительно от скорости математических вычислений, эффективности исполнения ветвлений или скорости текстурных выборок, а от всего понемногу. Для достижения высокой скорости тут важен баланс блоков GPU, также весьма заметно влияет на скорость и эффективность выполнения ветвлений в шейдерах. Сравнительные результаты видеокарт AMD на диаграмме в целом похожи на то, что мы видели в тесте текстурной производительности из 3DMark Vantage, кроме того, что новый Radeon HD 7970 явно эффективнее и в этой задаче, ведь он снова почти догнал двухчиповую HD 6990 — отличный результат! Платы Nvidia в данном случае получили некоторое увеличение производительности, что подтверждает вывод о том, что не только текстурная производительность влияет на результаты этого теста. Итак, новая модель компании AMD отлично выступила, совсем немного уступив двухчиповой плате на базе двух Cayman. Одночипового предшественника она обогнала на 66%. Эта цифра не соответствует ускорению от Cayman к Tahiti ни по одному из теоретических параметров и может означать улучшение эффективности исполнения сложных вычислений с ветвлениями. Даже считавшийся ранее неплохим результат Geforce GTX 580 вдвое хуже, чем у новинки AMD. Собственно, все видеокарты этого производителя оказались быстрее топовой модели линейки Geforce GTX 500 на базе одного чипа. Feature Test 4: GPU ClothТест интересен тем, что рассчитывает физические взаимодействия (имитация ткани) при помощи видеочипа. Используется вершинная симуляция, при помощи комбинированной работы вершинного и геометрического шейдеров, с несколькими проходами. Используется stream out для переноса вершин из одного прохода симуляции к другому. Таким образом, тестируется производительность исполнения вершинных и геометрических шейдеров и скорость stream out. Скорость рендеринга в этом тесте также зависит от многих параметров, но уже других. Основными факторами тут являются производительность обработки геометрии и эффективность выполнения геометрических шейдеров. Так что вполне логично, что именно видеокарты производства Nvidia чувствуют себя в этом приложении отлично, значительно опережая конкурентов. И даже представленная сегодня Radeon HD 7970, несмотря на явное улучшение производительности, по сравнению с HD 6970, не смогла тут составить конкуренцию одночиповой Geforce GTX 580 и немного уступила ей. Это один из тех геометрических тестов, в которых видно преимущество у недавно видеокарт HD 6900 перед предыдущими линейками, в которых увеличили скорость обработки геометрии и выполнения геометрических шейдеров. Radeon HD 7970 улучшила результат ещё на 35%, но этого оказалось мало — решения Nvidia продолжают лидировать в этом тесте. Хотя отметим, что новая модель всё же значительно улучшила позиции компании AMD в геометрических тестах. Feature Test 5: GPU ParticlesТест физической симуляции эффектов на базе систем частиц, рассчитываемых при помощи видеочипа. Также используется вершинная симуляция, каждая вершина представляет одиночную частицу. Stream out используется с той же целью, что и в предыдущем тесте. Рассчитывается несколько сотен тысяч частиц, все анимируются отдельно, также рассчитываются их столкновения с картой высот. Аналогично одному из тестов нашего RightMark3D 2.0, частицы отрисовываются при помощи геометрического шейдера, который из каждой точки создает четыре вершины, образующих частицу. Но тест больше всего загружает шейдерные блоки вершинными расчётами, также тестируется stream out. Результаты очередного теста из пакета 3DMark Vantage похожи на те, что мы видели на предыдущей диаграмме, но скорость обработки геометрии в нём стала ещё важнее. И поэтому видеокарты Nvidia вывались вперёд ещё дальше, оставив позади даже двухчипового монстра — Radeon HD 6990. Увы, но это факт — даже GTX 580 обогнала все платы AMD, в том числе и новёхонькую модель на базе графического процессора Tahiti. Увы, но хотя плата, основанная на новом чипе, и показала более сильный результат, по сравнению с решениями на базе Cayman и Cypress, но от Geforce отстало. Разница между HD 7970 и HD 6970 в этом сравнении составила чуть больше 30%, что указывает на явное влияние скорости ALU. В синтетических тестах имитации тканей и частиц из тестового пакета 3DMark Vantage, в которых активно используются геометрические шейдеры, решения AMD продолжают отставать от конкурирующих видеокарт соперника, имеющих весьма высокую скорость обработки геометрии. Feature Test 6: Perlin NoiseПоследний feature-тест пакета Vantage является математически-интенсивным тестом видеочипа, он рассчитывает несколько октав алгоритма Perlin noise в пиксельном шейдере. Каждый цветовой канал использует собственную функцию шума для большей нагрузки на видеочип. Perlin noise — это стандартный алгоритм, часто применяемый в процедурном текстурировании, он использует очень много математических расчётов. Интересно, что в математическом тесте из пакета компании Futuremark, показывающем пиковую производительность видеочипов в предельных задачах, мы увидели совершенно иную картину, по сравнению с аналогичными тестами из нашего тестового пакета. Показанная на диаграмме производительность решений лишь очень примерно соответствует тому, что должно получаться по теории, а также расходится и с тем, что мы видели ранее в математических тестах из пакета RightMark 2.0. Например, явно видно, что новая видеокарта в этом тесте подобралась гораздо ближе к теоретической скорости, по сравнению с картами на GPU с VLIW-архитектурой. Давайте разберёмся в причинах. В своё время, HD 6970 не усилила пиковую производительность математических вычислений по сравнению с HD 5870, но одним этим отставания Cayman не объяснить. Причиной могла быть как меньшая эффективность архитектуры VLIW4, так и умная система управления питанием, «зарезавшая» тактовую частоту и производительность решений при достижении установленного порога энергопотребления. Но ведь на HD 7970 она не сказалась. Скорее всего, причина как раз в скалярной архитектуре нового чипа. Потому что соотношение цифр производительности в тесте и теоретических на это явно указывает. По теории, HD 6970 обладает 0,7 математической мощи новой карты, но по этому тесту получилось лишь 0,56. Примерно такая же разница получилась и для других плат AMD. А вот при сравнении GTX 580 и HD 7970, имеющих скалярные архитектуры, теоретическое соотношение равно 0,42 (Tahiti более чем вдвое быстрее), и практическое тоже 0,42. То есть, эффективность использования имеющихся ALU у этих чипов разных производителей абсолютно одинаковая! В отличие от Cayman и Cypress, имеющих VLIW архитектуру. В любом случае, обеих своих конкурентов от Nvidia новая плата AMD обходит с огромным запасом, и Nvidia явно нужно резко усилить математическую мощь в будущих решениях. А пока что получается привычная картина — видеокарты Geforce показывают низкие результаты в таких случаях, когда простая и интенсивная математика выполняется на платах Radeon значительно быстрее. И выход Southern Island только усугубил ситуацию. Direct3D 11: Вычислительные шейдерыЧтобы протестировать новые решения компании AMD в задачах, использующих такие новые возможности DirectX 11, как тесселяция и вычислительные шейдеры, мы воспользовались примерами из пакетов для разработчиков (SDK) и демонстрационными программами компаний Microsoft, Nvidia и AMD. Сначала рассмотрим тесты, использующие вычислительные (Compute) шейдеры. Их появление — одно из наиболее важных нововведений в последних версиях DX API, они уже используются в современных играх для выполнения различных задач: постобработки, симуляций и т. п. В первом тесте показан пример HDR-рендеринга с tone mapping из DirectX SDK, с постобработкой, использующей пиксельные и вычислительные шейдеры.
Возможно, это и не самый удачный пример для вычислительных шейдеров, но разницу в производительности показывает довольно чётко. Разницы между расчётами в вычислительном и пиксельном шейдерах для видеокарт AMD почти нет, а на Nvidia немного быстрее выполняется пиксельный. AMD Radeon HD 6970 оказалась быстрее предшественницы HD 5870, и выступила на уровне Geforce GTX 580, но представленная сегодня модель HD 7970 значительно опережает их все и становится лидером (двухчиповые видеокарты в этой синтетике мы решили не использовать). GTX 560 Ti взята в основном для тестов геометрии, ну и для того, чтобы оценить разницу между решениями из разных ценовых сегментов. Итак, анонсированные плата на новом чипе Tahiti опережает аналог на базе Cayman на 40%, что полностью соответствует разнице в теоретической производительности вычислительных блоков. В свою очередь, преимущество над конкурирующей GTX 580 равно 30-40% (в зависимости от типа шейдерной программы), что явно ниже теоретически возможного. GTX 560 Ti отстаёт очень сильно, более чем вдвое. Второй тест вычислительных шейдеров также взят из Microsoft DirectX SDK, в нём показана расчётная задача гравитации N тел (N-body) — симуляция динамической системы частиц, на которую воздействуют физические силы, такие как гравитация.
Результаты в этом тесте весьма необычные, для устаревших решений AMD похожие на цифры из математического теста 3DMark Vantage — Cypress оказался быстрее Cayman. Несмотря на большое теоретическое превосходство в пиковых цифрах, быстрейшая видеокарта AMD — представленная сегодня новинка Radeon HD 7970 — лишь на 21% опережает топовое решение Nvidia. И даже GTX 560 Ti не так уж сильно отстаёт. Старые модели семейств HD 6900 и HD 5800 показывают результаты, близкие к показателям Geforce GTX 580. Больше всего нам интересна разница между результатами решений на Cayman и Tahiti, и в этом случае мы видим преимущество свежей модели, равное 36%. Это чуть меньше теоретической разницы между данными моделями, но всё-таки близко к ней. Почему же обе карты не очень ярко выступили на фоне очень старой HD 5870? Возможно, виновата сниженная PowerTune частота или недостаток оптимизации драйверов под новую архитектуру. Посмотрим, может в тестах тесселяции Tahiti наконец-то покажет значительное ускорение. Direct3D 11: Производительность тесселяцииВычислительные шейдеры очень важны, но главным нововведением в Direct3D 11 всё же считается аппаратная тесселяция. Мы очень подробно рассматривали её в своей теоретической статье про Nvidia GF100. Тесселяцию уже довольно давно начали использовать в DX11-играх, таких как STALKER: Зов Припяти, DiRT 2, Aliens vs Predator, Metro 2033, Civilization V, Crysis 2, Battlefield 3 и других. В некоторых из них тесселяция используется для моделей персонажей, в других — для имитации реалистичной водной поверхности или ландшафта. Существует несколько различных схем разбиения графических примитивов (тесселяции). Например, phong tessellation, PN triangles, Catmull-Clark subdivision. Так, схема разбиения PN Triangles используется в STALKER: Зов Припяти, а в Metro 2033 — Phong tessellation. Эти методы сравнительно быстро и просто внедряются в процесс разработки игр и существующие движки, поэтому и стали популярными. Первым тестом тесселяции будет пример Detail Tessellation из ATI Radeon SDK. В нём реализована не только тесселяция, но и две разные техники попиксельной обработки: простое наложение карт нормалей и parallax occlusion mapping. Что ж, сравним DX11-решения AMD и Nvidia в различных условиях:
Интересно, что parallax occlusion mapping (средние столбики на диаграмме) на видеокартах от обоих производителей выполняется гораздо менее эффективно, чем тесселяция (нижние столбики), а умеренная тесселяция не даёт большого падения производительности — сравните верхние и нижние столбцы. То есть качественная имитация геометрии при помощи пиксельных расчётов обеспечивает даже меньшую производительность, чем оттесселированная геометрия с displacement mapping. Что касается производительности видеокарт относительно друг друга, то давайте рассмотрим сначала попиксельные техники. В тесте простого бампмаппинга лидирует новая видеокарта AMD, она опережает и HD 6970 и GTX 580 на 27% и 36% соответственно. А вот в подтесте сложных попиксельных расчётов (вспоминаем тесты parallax mapping выше по тексту) до выхода Cayman видеокарты Geforce были быстрее решений AMD, равно как и при включенной тесселяции. С выходом Radeon HD 6970 в подтесте с тесселяцией оказались заметно быстрее HD 5870, и в тесте с небольшим коэффициентом разбиения треугольников HD 6970 обогнала даже GTX 580. Гораздо интереснее то, что мы увидели на графике с меткой Radeon HD 7970. Тесселяция тут не слишком сложная, поэтому новая видеокарта выиграла у предшествующей модели не так уж много — около 30%. Другое дело — тест POM. В этом подтесте новая HD 7970 просто разорвала все остальные решения в клочья. Преимущество перед HD 6970 и GTX 580 лишь немного не дотягивает до двукратного. Очередной суперрезультат в тесте parallax mapping, говорящий о высокой эффективности исполнения сложных шейдерных программ. Вторым тестом производительности тесселяции будет ещё один пример для 3D-разработчиков из ATI Radeon SDK — PN Triangles. Собственно, оба примера входят также и в состав DX SDK, так что мы уверены, что на их основе создают свой код игровые разработчики. Этот пример мы протестировали с различным коэффициентом разбиения (tessellation factor), чтобы понять, как сильно влияет его изменение на общую производительность.
А вот в этом примере мы видим уже полноценное сравнение геометрической мощи решений AMD и Nvidia в разных условиях. И оно получилось весьма интересным, на наш взгляд. Сильно выделяется графическая архитектура Fermi, да и чип новой архитектуры Tahiti от AMD. Конечно, это чисто синтетический тест и экстремальные коэффициенты разбиения вряд ли будут использоваться в играх ближайшего времени, особенно учитывая тотальную мультиплатформенность. Нам интересен архитектурный потенциал, для чего и нужна «синтетика». Если в лёгких условиях новая Radeon HD 7970 успешно конкурирует с Geforce GTX 580, опережая её в самых лёгких режимах и идёт наравне в третьем, но в самых тяжёлых условиях с очень большим количеством треугольников с видеокартой Nvidia Geforce на чипе GF110 конкурировать просто невозможно — в задачах экстремальной тесселяции она значительно быстрее даже неоднократно улучшенных чипов AMD. Новый GPU хотя и ещё раз сократил отставание от конкурента в задачах обработки геометрии, но до распараллеленной работы 16 блоков тесселяции в GF110 всё ещё очень далеко. И даже GF114 при максимальном коэффициенте разбиения оказался быстрее Tahiti. Тем не менее, несмотря на проигрыш в наиболее суровых условиях с максимальным коэффициентом разбиения, в остальном HD 7970 на базе Tahiti выступила просто отлично, особенно по сравнению с Cayman и Cypress. Новая модель компании AMD в режимах лёгкой и средней нагрузки показывает впечатляющий прирост в скорости, и разница по сравнению с и так не медленной HD 6970 достигает 2,8 раза. Но такой прирост мы видим только в экстремальном случае, а чаще всего получается от 30 до 70%. Обещанной четырёхкратной разницы мы не увидели, по крайней мере пока. Но максимальная разница между решениями компаний достигается в условиях экстремальной тесселяции, которых не будет в играх и приближённых к ним бенчмарках. Поэтому мы ожидаем, что Tahiti заметно улучшит позиции компании AMD в существующих тестах с применением тесселяции, вроде 3DMark11 и Heaven. Давайте рассмотрим ещё один тест — демонстрационную программу Nvidia Realistic Water Terrain, также известную как Island. В этой демке используется тесселяция и карты смещения (displacement mapping) для рендеринга реалистично выглядящей поверхности океана и ландшафта. Смотрится она просто замечательно, вот чего не хватает в нынешних играх:
Island не является чисто синтетическим тестом для измерения геометрической производительности, он содержит и сложные пиксельные и вычислительные шейдеры, и такая нагрузка ближе к реальным играм, в которых используются сразу все блоки GPU, а не только геометрические, как в предыдущем бенчмарке. Мы также протестировали программу при четырёх разных коэффициентах тесселяции, эта настройка называется Dynamic Tessellation LOD. И если при самом низком коэффициенте разбиения впереди оказываются все видеокарты компании AMD, то при усложнении работы платы на основе чипов от Nvidia начинают вырываться вперёд. И при увеличении коэффициента разбиения и сложности сцены производительность абсолютно всех Radeon падает сильно, в отличие от конкурирующих решений. Поведение Radeon HD 7970 в тесте любопытное. Сразу видно, что никаких кардинальных изменений в геометрическом конвейере сделано не было (в общем, это и не обещалось, так что никаких претензий). Если в самом лёгком режиме новая карта быстрее HD 6970 на 35%, а GTX 580 — на 64%, то уже при настройке LOD в значение 25 производительность новинки падает до уровня скорости GTX 560 Ti. Дальше — больше. При максимальном коэффициенте LOD разница между скоростью Geforce GTX 580 и Radeon HD 7970 достигла 3,5 раз! Проверим, получили ли мы обещанную четырёхкратную разницу между HD 7970 и HD 6970. Нет, максимальное отставание графического процессора Cayman составило менее чем два раза. А чаще всего и вовсе лишь полтора. В общем, нам не очень понятно, где искать четырёхкратное ускорение тесселяции, остаётся верить на слово, что где-то оно есть. Пока же констатируем очередную победу видеочипов от Nvidia — уж очень они хороши в геометрических тестах. Выводы по синтетическим тестамПо результатам проведённых нами синтетических тестов новейшей видеокарты Radeon HD 7970, основанной на графическом процессоре Tahiti из семейства Southern Islands, а также результатам других моделей видеокарт производства обоих производителей дискретных видеочипов, можно сделать вывод о том, что новинка определённо станет лидером среди одночиповых решений, доступных на рынке. Это просто отличное продолжение удачных линеек Radeon HD 5800 и HD 6900, которое должно серьёзно укрепить позиции компании AMD в ближайшие месяцы. Графический процессор Tahiti выполнен на основе новой архитектуры с применением самого современного техпроцесса 28 нм, и он очень сильно отличается от всех предыдущих чипов компании. Хотя количество некоторых исполнительных блоков в нём выросло не так значительно (вычислительные блоки ALU и блоки ROP), но новый GPU отличается важными архитектурными изменениями, направленными на увеличение эффективности вычислений на GPU, а также на улучшение позиций в производительности обработки геометрических данных. Многие из наших синтетических тестов показали, что эффективность вычислений в сложных задачах и скорость тесселяции и выполнения геометрических шейдеров серьёзно выросли, хотя и не всегда настолько, насколько нами ожидалось. С видеочипами AMD случилось то, что обязано было случиться. То самое, что Nvidia уже прошла чуть раньше. При переносе акцента с графических вычислений на вычисления общего назначения, и соответствующем переходе от VLIW к скалярным архитектурам, а также добавлении других важных для GPGPU функций, вроде продвинутого кэширования и добавления планировщиков в каждый вычислительный блок, рост сложности чипа обязательно превысит рост пиковых показателей производительности. То есть, чисто фактически получается, что предыдущие решения могут быть эффективнее — хотя они менее производительны, но достигается это меньшими силами (в виде сложности чипа). Поясним это на примере. Преимущество Radeon HD 7970 перед тем же Radeon HD 5870 в некоторых синтетических тестах было далеким от разницы в сложности GPU — ведь Cypress имеет ровно вдвое меньше транзисторов (2,15 против 4,3 млрд), а в тестах очень редко отстаёт настолько же сильно. Получается, что старый чип эффективнее нового? Да, но только для устаревающих чисто графических задач! В случае же неграфических вычислений, да и многих сложных 3D-расчётов, Tahiti оказался даже более чем вдвое мощнее Cypress, и это подтверждается соответствующей синтетикой. За GPGPU будущее, и задачи видеочипов будут усложняться и далее, поэтому иного пути у AMD просто не было. Зато, благодаря архитектурным изменениям и своим характеристикам, видеокарта новой серии во многих синтетических тестах, которые ранее были «ахиллесовой пятой» решений AMD, стала более чем конкурентоспособной, особенно по сравнению с прямым конкурентом Geforce GTX 580, даже с учётом большей цены. Это отлично видно почти во всех синтетических тестах пакетов RightMark, Vantage, да и примерах из различных SDK. Но нашлись и потенциально… ну, не то, чтобы слабые, но недостаточно сильные стороны нового GPU. К таким относится не слишком большой рост производительности в некоторых математических тестах, да и по геометрическим возникают вопросы (например, где обещанное четырёхкратное ускорение?). Несмотря на бо́льшую сложность и площадь чипа по сравнению с тем же Cayman, результаты модели HD 7970 иногда ниже ожидаемых, что не всегда можно легко объяснить. Мы предполагаем, что в этом может быть виноват недостаток оптимизации драйверов, ведь для AMD эта архитектура абсолютно новая и требует тщательной и длительной шлифовки. В некоторых тестах могла подвести и система управления питанием PowerTune, которая могла понизить тактовые частоты при достижении максимального энергопотребления в наиболее требовательных синтетических тестах, не позволяя карте показать ожидаемую производительность, исходя из числа исполнительных блоков и их тактовой частоты. Хотя в целом результаты в синтетике были показаны весьма неплохие, и особенно приятно то, что инженеры AMD подтянули некоторые из своих слабых мест. К сожалению, в текущих играх гораздо сложнее будет добиться столь впечатляющих приростов, по сравнению с продвинутой синтетикой. Сразу по нескольким причинам. Даже просто потому, что производительность в игровых приложениях редко ограничена какой-то одной характеристикой видеокарты, в отличие от синтетики, а при такой радикальной смене графической архитектуры драйверы ещё нужно оптимизировать и оптимизировать. Кроме того, даже современные игры редко используют все возможности топовых видеокарт для ПК. Они часто упираются в скорость текстурных выборок и эффективный филлрейт (пропускную способность видеопамяти), а в таких условиях полностью раскрыться столь сложные чипы не могут. Придётся ждать или мощных ПК-эксклюзивов или следующего поколения игровых консолей. Предполагаем, что результаты Radeon HD 7970 в синтетических тестах будут подтверждены соответствующими цифрами и в «игровой» части нашего материала. В играх новая HD 7970 должна выступить сильнее всех конкурентов и опередить Geforce GTX 580 хотя бы на 30%, а то и больше. Вероятно, получится как обычно — в некоторых тестах преимущество будет больше, а в других — его почти не будет. В любом случае, HD 7970 обязана стать лучшей среди всех одночиповых моделей AMD и Nvidia, по крайней мере, все предпосылки к этому мы нашли. Так давайте же перейдём к следующей части материала — исследованию скорости в играх. | |